
인간은 아주 오래 전에 정보를 저장하기 시작했다. 고대에는 관공서, 도서관, 병원 및 비즈니스 조직에 의해 정교한 데이터베이스 시스템을 개발했으며 이러한 시스템의 기본 원칙 중 일부는 오늘날에도 사용되고 있습니다.
DBMS는 컴퓨터가 발명된 이후 데이터의 수집/갱신/조회의 효율화를 위한 수단의 한가지로 DBMS가 큰 역활을 담당해 왔며 시대에 따라서 그 발전 방향이 바뀌어 왔다
2000년데 이전까지는 RDBMS시대로 데이터에 ACID의 정합성 및 효율화의 시기였다면, 2000년대 이후로는 Big Data가 시대의 흐름에 맞춰 NoSQL DBMS가 생겨나기 시작 했으며, NoSQL의 단점을 보완한 NewSQL로도 발전을 하고 있다
RDBMS/NoSQL/NewSQL는 모두 장단점을 가지고 있으며 각각의 상황에 맞는 역활들을 충분히 가지고 있다, 그러므로 시스템 상황에 맞는 DBMS를 선택 사용하면 된다.
[1]. 데이터 베이스의 탄생과 발전 역사 (A Brief History of Database Management)
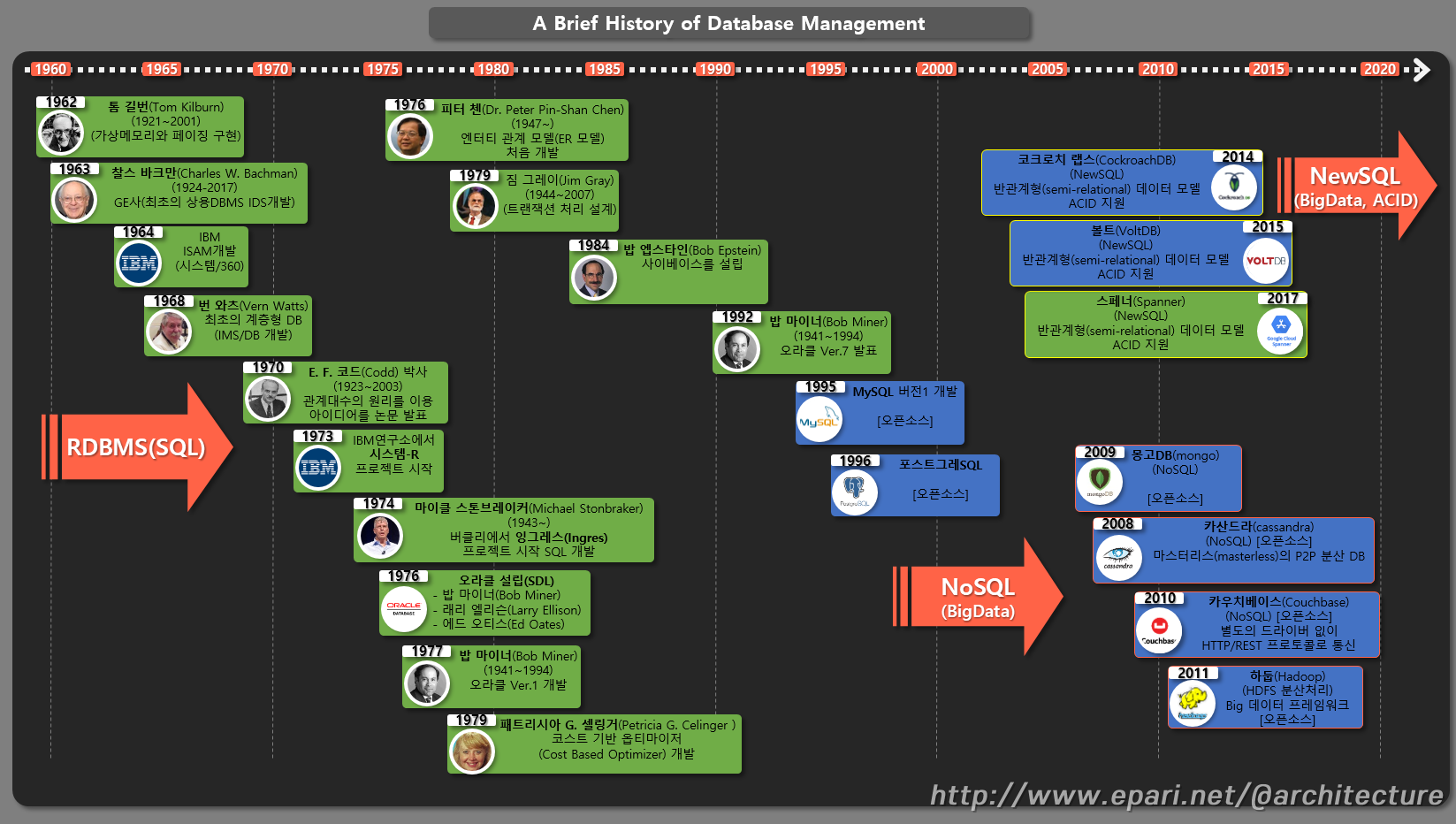
1. RDBMS(SQL)
- 랜덤 액세스 디지털 스토리지, 가상 메모리 및 멀티 프로그래밍을 포함한 초기 컴퓨터 디자인에 기여했으며, 이 아이디어는 DBMS의 버퍼 캐시를 관리하기 위한 알고리즘의 토대가 됐다.
- 1963 : 찰스 바크만(Charles W. Bachman)
- 제너럴 일렉트릭(GE)에서 데이터를 독립적으로 관리하기 위해 IDS(Intergrated Data Store)를 만들었으며, 이는 최초의 상용DBMS로 평가 받는다
- 1960년대 에는 코볼 언어의 개발/데이터베이스 인터페이스 표준화를 진행했던 CODASYL의 네트워크 모델과 IBM의 IMS라는 계층 적 모델 두가지가 공존했지만, 이후 IBM의 IDS가 상업적 성공을 거두면서 네트워크 모델은 도태되었다.
- 1964 : IBM-ISAM개발(시스템/360)
- IBM은 시스템/360을 개발하면서 ISAM(Indexed Sequential Access Method)인덱스의 개념을 처음으로 도입,이후 VSAM, B 트리 인덱스로 변형되고 발전했는데, 이는 데이터를 최초로 구조화했다는데 그 의미가 있었다.
- IBM의 번 와츠(Vern Watts) 등 IBM 연구진과 공동으로 계층형 DBMS를 개발하기 시작했으며, 최초의 계층형 DB(IMS/DB 개발)개발 성공
- IBM연구소의 수학자인 E. F. 코드(Codd) 박사는 수학적 관점에서 데이터관리를 효율적으로 관리하기위해 관계 대수의 원리를 이용해 저장하고 조회하면 된다는 아이디어를 논문으로 발표
- 1973 : IBM에서 System-R 프로젝트 시작
- SQL이 처음 만들어짐
- 1974 : 마이클 스톤브레이커(Michael Stonbraker)
- Buerkeley에서 잉그레스(Ingres) 프로젝트로 RDBMS연구 시작, 잉그레스 프로젝트는 이후 소스가 오픈됐고, 이후 개발되는 많은 DBMS의 모태가 됐다
(Ingres, Postgres95, PostgresSQL, VectorWise, Monet DB,Netezza, Greenplum, Redshift, Illusta, DATAllegro, Aster Database)
E. F. 코드 박사의 논문의 영향으로 SDL이라는 회사를 설립
- 밥 마이너(Bob Miner)
- 래리 엘리슨(Larry Ellison)
- 에드 오티스(Ed Oates)
- 1976 : 피터 첸(Dr. Peter Pin-Shan Chen)
엔터티 관계 모델(ER 모델) 처음 개발
- 오라클 Ver.1 개발
- 1979 : 패트리시아 G. 셀링거(Petricia G. Celinger )
- 코스트 기반 옵티마이저(Cost Based Optimizer) 개발
-트랜잭션 처리 설계
- 1984 : 밥 엡스타인(Bob Epstein)
- 사이베이스를 설립
- 오라클 Ver.7 발표
- 1995 : [오픈소스] MySQL 버전1 개발
- Postgres95는 SQL의 해석기에 SQL질의어를 추가하여 PostgresSQL으로 변경
2. NoSQL
- 2009 : [오픈소스] 몽고DB(mongo)
- 2008 : [오픈소스] 카산드라(cassandra)
- 마스터리스(masterless)의 P2P 분산 DB
- 2010 : [오픈소스] 카우치베이스(Couchbase)
- 별도의 드라이버 없이 HTTP/REST 프로토콜로 통신
- HDFS 분산처리 Big 데이터 프레임워크
3. NewSQL
- 반관계형(semi-relational) 데이터 모델, ACID 지원
- 반관계형(semi-relational) 데이터 모델, ACID 지원
- 2014 : 코크로치 랩스(CockroachDB)
- 반관계형(semi-relational) 데이터 모델, ACID 지원
- 반관계형(semi-relational) 데이터 모델, ACID 지원
- 반관계형(semi-relational) 데이터 모델, ACID 지원
[2]. 관계형 데이터베이스 관리 시스템의 계보(Genealogy of Relational Database Management Systems) - 1/2
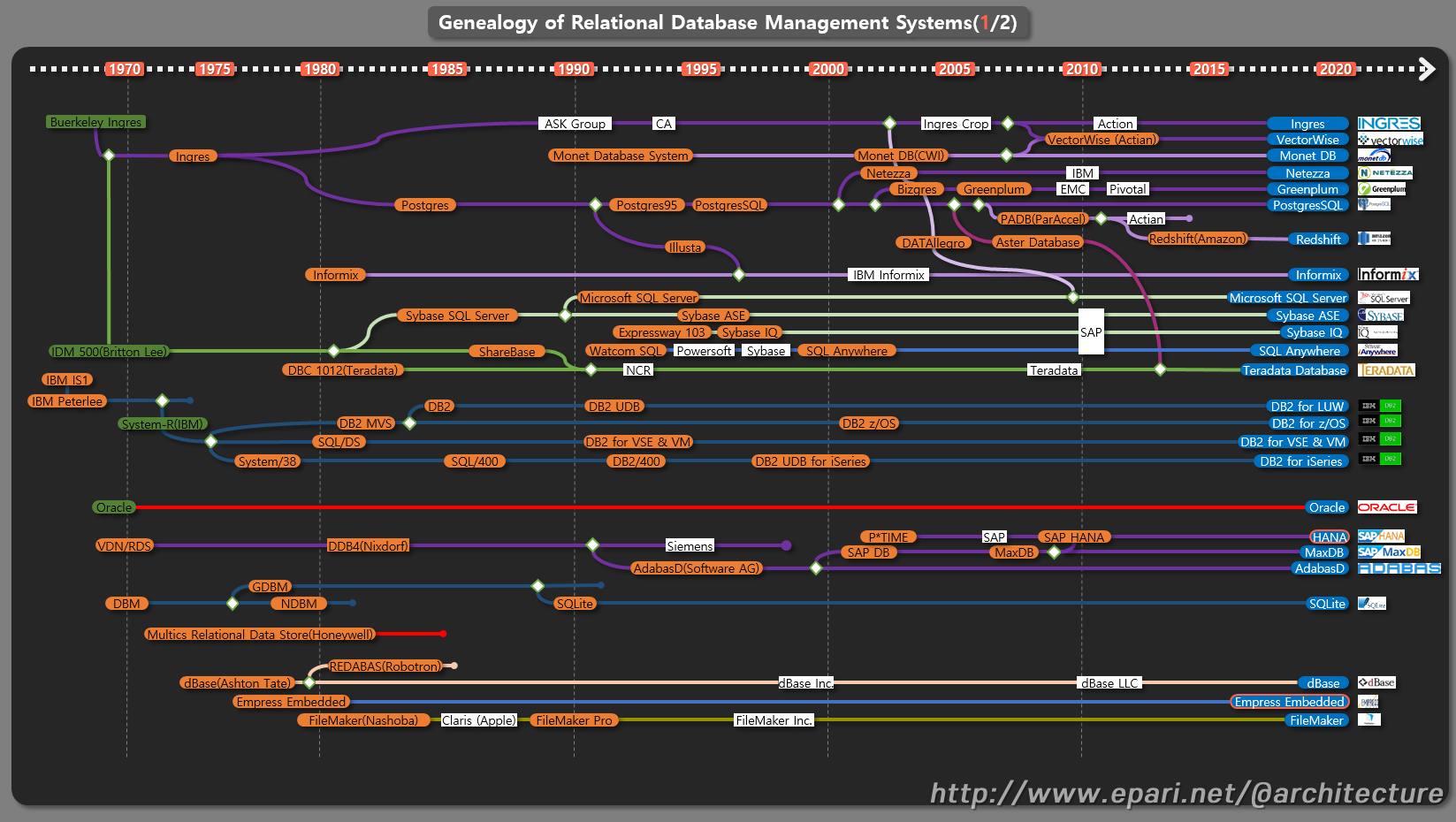
[3]. 관계형 데이터베이스 관리 시스템의 계보(Genealogy of Relational Database Management Systems) - 2/2

RDBMS 특징
- 보안성과 안정성이 좋음
- 일관성과 신뢰성이 높음
- 동시성이 가능함
- 복잡한 쿼리가 수행이 가능(복잡한 비즈니스 로직 처리가 가능함)
- 대용량 데이터에 대한 워크로드가 발생
- 대량 데이터의 실시간 분석에 맞지 않음
- 상대적으로 고비용
- 트랜잭션을 위한 ACID 지원 : 트랜잭션 커밋(Commit)을 위한 필요속성인 ACID( 원자성, 일관성, 고립성, 지속성)을 지원
- 원자성(Atomicity) : 트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는 능력
- 일관성(Consistency) : 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지
- 고립성(Isolation) : 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장
- 지속성(Durability) : 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함
[4]. NoSQL / NewSQL 데이터베이스 관리 시스템의 계보 (Genealogy of NoSQL/NewSQL Database Management Systems)
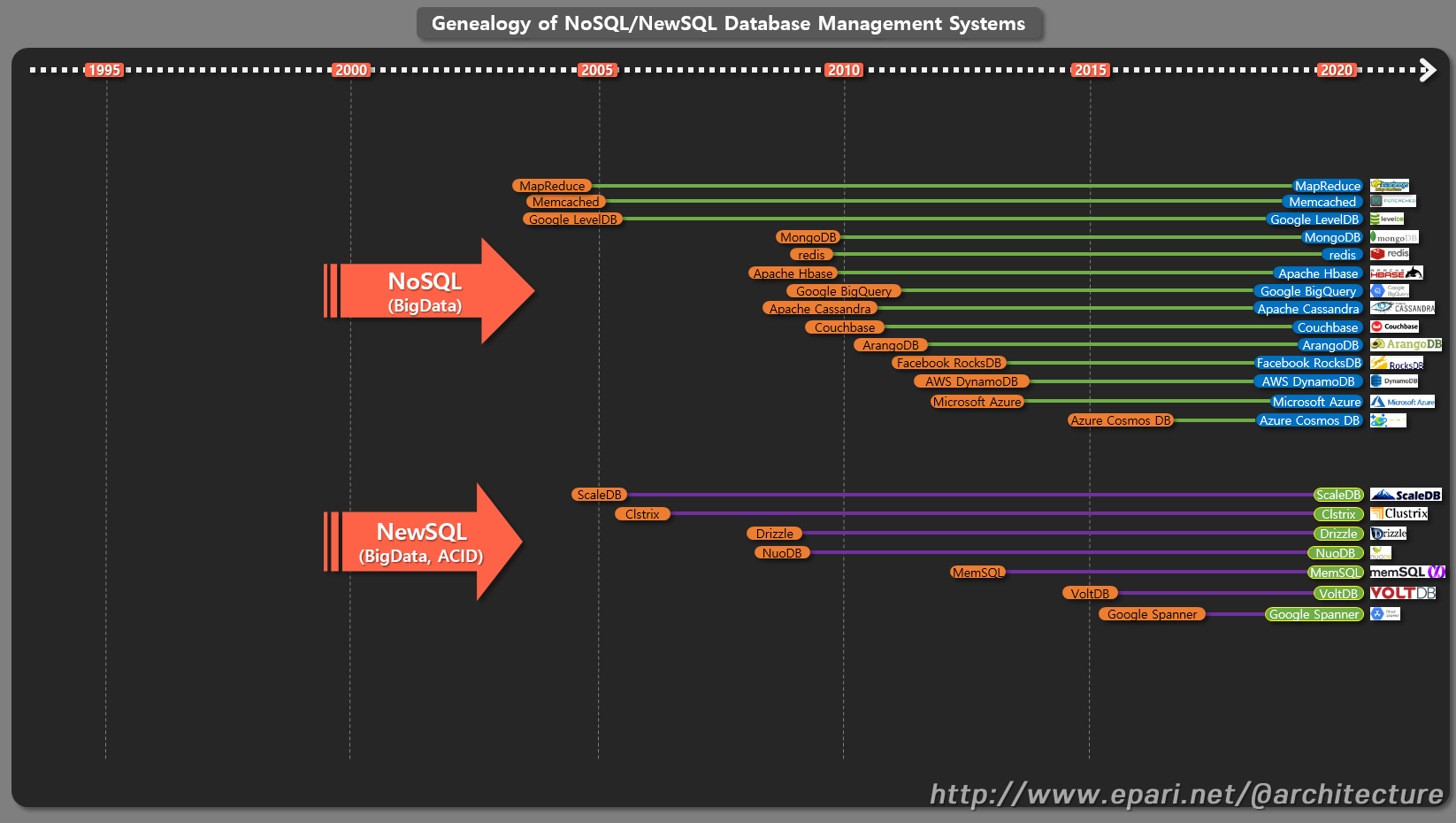
NoSQL 특징
- 대용량 데이터에 적합함
- 데이터 추가가 유연함
- 용량 대비 비용이 좋음
- 트랜잭션을 지원하지 안아 높은 수준의 데이터 정합성을 필요로 분야에서는 사용할수 없음
- SQL과 같은 표준 언어가 없다
- 보안이슈가 RDBMS보다는 낮음
NewSQL 특징
- 대규모 트랜잭션을 감당할수 있는 분산처리 기술과 이키텍처
- RDBMS의 트랜잭션 기능을 포함하고, NoSQL의 확정성과 가용성을 가지고 있음
- RDBMS나 NoSQL의 SQL보다 복잡하다
- 표준이 없음
- 데이터 무결성 처리를 위해 지원하는 트랜잭션 동시제어 잠금처리와 관련해 기존 방식과는 다른 Non-locking 구조를 지원
- 락을 걸지않고 단일 스케줄을 통해 동시성 제어를 한다.
- 각 단일 DBMS 서버 노드 단위로 확장해 고성능 보장
- 네트워크를 통한 처리가 없고 Node 단위로 확장하여 성능을 높일 수 있다.
- 병렬적으로 수행해서 데이터를 고성능으로 처리 할 수 있어야하고, 분산 처리 시 데이터가 각 서버에 중복되지 않고 독립적으로 존재해야 한다.
- CPU, RAM, DISK 같은 하드웨어 자원을 서로 공유하지 않고 개별적으로 사용한다.
- Sharding를 통해 Scale-out을 지원한다.
- Sharding : 같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법, 읽기 또는 검색 속도를 높일수 있다
- Partitioning : 테이블 데이터 에서 컬럼의 값을 기준으로 분할
- Concurrency Control : MVCC(Multi Version Concorrencty Control) 기법 적용
- NewSql은 트랜잭션에 의해 데이터 갱신이 발생 할때, 생성된 사본에 데이터를 갱신하는 연산을 수행하므로 다른 트랜잭션에 영향을 끼치지 않으면서 빠른 성능을 구현이 가능하다
- 서버의 Node단위로 운영하면서 하나 이상의 노드에 문제가 생길경우, 데이터를 복구하고 상태를 유지하는 것이 가능하다.
- Disk Raid 1과 비슷한 개념이다. 물리적인 디스카 하나가 고장 나면 다른 Disk(미러링된)의 데이터로 운영 및 복구가 가능하다, 다른점은 NewSQL Database는 여러개의 Node에 중복(미러링) 데이터를 Read할때 정해진 블록으로 여러 Node에서 분산해서 읽어 오기때문에(Disk의 병목현상을 극복) 읽기 속도가 빠르다
- In-Memory DB : 실시간 저장 및 처리를 위해서 인메모리 DB 아키텍처이다.
- 모든 NewSql이 인메모리 DB는 아니지만, 대부분 지원한다.